
在知乎上关于 为什么前端工程师那么难招 这个问题里,一个答主说他招前端结果过来面试的很多连单向链表反转这种简单的面试题都写不出来。然后在微信群里也看到有人在讨论这个问题,就想着自己也来掺合一下,看看这道题到底是个啥。
说起来前端在实际工作中其实几乎遇不到链表这种数据结构,大部分人可能都是像我一样,知道链表是个什么东西,但也没有深入去了解和实现过,可能有的同学连链表是什么都不一定清楚,但其实在这道题上这并影响不大,还是很容易的,只要别上来就露怯,就算不知道链表是什么东西,也是八九能解出来的。不过话说真不知道的同学,还是应该去了解一下,万一下次被面到呢。。。
这篇博客,就记录一下我解这道题的一些思路和心得。
链表概述
首先我们来大概讲一下链表,链表故名思意,即链接在一起的一个类似列表的结构,它的每个节点都包含了当前值和下一个值的位置或引用。
也就是类似下面这种结构:
1 | LinkNode { |
每个节点都有一个 data 表示当前的值和一个 next 表示下一个节点的位置,这也就是我们今天的主角:单向链表。
所以也非常容易想到,双向链表就是一个节点不仅包含了下一个节点的位置,还包含上一个节点的位置。
用 js 来简单的表达一个单向链表,就是类似下面这样的一个对象
1 | { |
对象的每一层,即相当于链表的一个节点。
题干
知道了单向链表是什么之后,我们来看一下这道算法题:
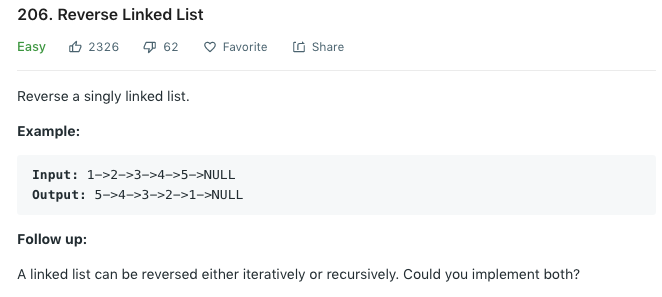
千万别以为它是让你反转字符串 1->2->3->4->5->NULL 为 5->4->3->2->1->NULL,要是面试时闹出这种乌龙那就有点糗了。具体的,是因为各个语言中链表的表示方式各不相同,因此 leetcode 就用这种形式来统一表示链表,方便大家用各种语言来解题嘛。
来详细的说,这道题题干看起来非常简单,输入一个类似如下的数据结构
1 | { |
需要将链表反转,即头变尾,尾变头,以如下形式输出:
1 | { |
另外题目还提示,可以使用循环和递归两种方式实现。
比较蠢的第一种解法
我们先来观察和思考一下,抛弃链表这个概念,单纯把它当成 js 对象来看,这个对象每一层的 next 值都指向下一层,直到最里层 next 值为 null 时结束。
我们需要做的是,将每一层的 next 都指向它的上一层,从而将这个对象反转过来。
那我们就先以最朴素的思想来实现一下它,假装我们还是当初那个可爱的傻瓜,先来个遍历循环再说,一个不够就两个,不信循环不出来它,当初咱在 for 循环里写 sql 都干过,这都不算啥。
来看,我们先把链表的每一层单独取出来得到一个我们熟悉的数组,然后再看着怎么处理这个数组,这不就一下又回到我们熟悉的 js 领域啦,不用管什么链表还是好啊,所以我们大概就写出了下面这种代码:
1 | var reverseList = function (head) { |
看起来还不错吧,我们首先遍历链表,把每一层的 val 取出来,然后把它的 next 链接置空,从而得到一个相当于还没有链接其他节点的单独节点,然后把这个节点从数组头填到一个数组里,然后再从头循环这个数组,一个一个的将所有节点链接起来,最后得到的就是我们想要的结果了。
OK,我们提交一下试试看
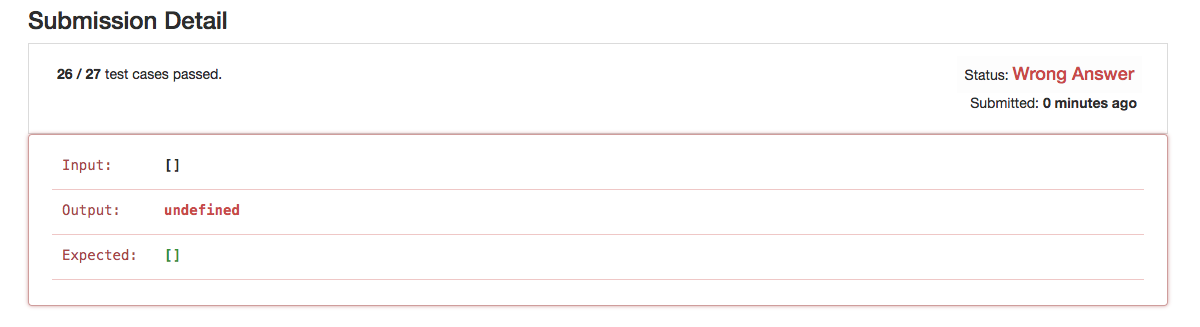
非常遗憾没有通过,原来我们忘记了空链表这种特殊情况了,补上防止链表参数为空的判断
1 | var reverseList = function(head) { |
这次顺利的通过了

但是看一下这个运行时间和占用内存,这个解法的时间复杂度和空间复杂度看起来都有些不乐观。可能有的水平比较高的同学现在已经嘴角带笑了,这个解法也太 low了吧,但别急着否定,这个解法虽然比较质朴,但从其中我们也可以提炼出不少有助于我们解题和优化的思路来的。
再回看一遍我们的解法,我们从链表的头部,也就是对象的最外层,一层一层的取到值,然后在到达链表尾部后,再从内向外一层一层的将链表的指向反转过来,这个行为让我们想到了什么?没错,就是先进后出的栈,一层层的压入,再一层层的取出,而我们声明的数组 arr,就类似于一个简略的栈,先遍历链表一个个填入,再遍历数组,一个个取出。
虽然过程是比较笨拙了些,但是只要思路有了,可以慢慢优化嘛。
平平无奇的第二种解法
第一个想法就是,如果我们可以不用两次遍历,而是在一次遍历过程中就同时取值和更新呢,看下面的代码:
1 | function reverseList(head) { |
我们设置了一个值 obj,然后在每次读取到链表的一层时,就重新赋值 obj 将它的 next 值指向它的旧值,这样我们在读取链表每个节点时,也同时更新和生成新的链表,从而达到只需要遍历一次,就可以完成反转的任务。
我们再提交试一下

不错哦,这次看起来快了不少,但是好像代码占用空间还是有点多啊,想想办法!
吊炸天的第三种解法
继续想一下,我们怎么优化才能少占用点内存呢?代码已经就这么几行了,好像没发整了。
再回头看一下前面的代码,哎,我们发现,我们创建了一个 obj 值,在遍历链表时,多次重新给它赋值,这可能会占用不少的内存,那我们可不可以不new 一个值,而是直接 in-place 原地操作呢?
因为实际上我们也只是需要改变链表每个节点的 next 指向而已,并不是什么复杂的操作,所以直接在链表上操作应该是可行的,多次尝试后,摸索得到了以下的代码
1 | var reverseList = function(head) { |
我们将前一个节点保存为 prev, 当前节点为 current,下一个节点为 next,然后通过遍历链表向前移动过程中的不断交叉赋值,实现了在链表上的原地操作。
再提交一下试试

效果相当明显,速度已经快到它姥姥都不认识了,基本已经击败了全国所有人,内存占用也降低了 70%(其实仔细对比一下也就 1M 而已哈哈),相比最初的那个循环两次的解法,不知道高到那里去了。
但仔细想一下,虽然这三个算法在速度上差距不小,但其实思路是类似的,都是从最外层遍历到最里层,然后一层层的处理,不同的是,
在第一个解法中,我们先遍历一遍输入取到值,再遍历一遍生成输出值
在第二个解法中,我们自己创建了一个值,然后在遍历输入值的过程中使用我们创建的值来配合进行操作,从而避免了两次遍历
而在第三个解法中,我们不再创建新值,而是直接在原输入值上操作,从而大幅提高了程序运行的速度,降低了内存占用
在一步步实现这三个解法的过程中,我们可以学到什么:
- 尽量减少遍历,遍历会增加程序的时间复杂度,也就是更慢
- 避免不必要的创建和赋值,会增加程序的空间复杂度,也就是占用更多内存
这也是我认为不管前端还是后端程序员,都应该也需要去学习算法的原因,在算法种种特殊的要求和规则下,我们才能对语言和数据结构具有更深层次的理解,才能体会到平常工作中难以接触的更多的程序优化思路,才能更严苛的追求速度和性能的最优解,而这种本领,是比各种语言和框架更宝贵的,真正的屠龙之技。
到了这里,这篇博客也基本结束,转眼间已经三四个月没再动手写过东西了,自责一下,唉。。。
自责完了,顺带提一下,题目里说这道题也可以使用递归的方法解决,所以我们也可以试着将 while 循环改为递归的方式,从而使代码更简洁一些,如下:
1 | var reverseList = function (head, obj = null) { |
上面这个函数我们还可以使用箭头函数再简化一下,变成这种形式
1 | var reverseList = (head, obj = null) => head === null ? obj : reverseList(head.next, { val: head.val, next: obj }) |
当然,这样可读性有那么些太低了,所以除非人为的需要去装一些 X 的时刻, 其他时候完全没必要。
以上就是本篇博客的全部内容,感谢阅读。